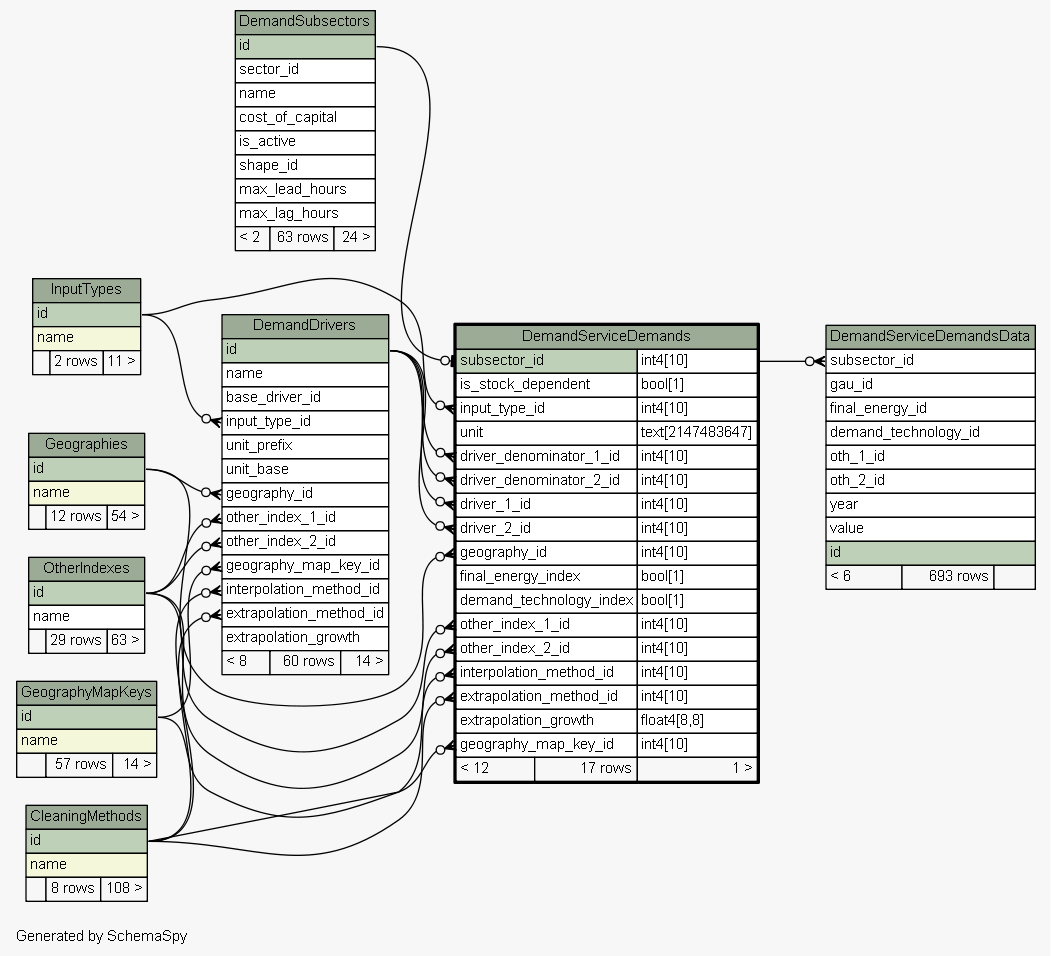
| subsector_id |
int4 |
10 |
|
|
|
|
|
| is_stock_dependent |
bool |
1 |
√ |
|
false |
|
|
| input_type_id |
int4 |
10 |
√ |
|
null |
|
| InputTypes.id
|
DemandServiceDemands_input_type_id_fkey R |
|
| unit |
text |
2147483647 |
√ |
|
null |
|
|
| driver_denominator_1_id |
int4 |
10 |
√ |
|
null |
|
| DemandDrivers.id
|
DemandServiceDemands_driver_denominator_1_id_fkey R |
|
| driver_denominator_2_id |
int4 |
10 |
√ |
|
null |
|
| DemandDrivers.id
|
DemandServiceDemands_driver_denominator_2_id_fkey R |
|
| driver_1_id |
int4 |
10 |
√ |
|
null |
|
|
| driver_2_id |
int4 |
10 |
√ |
|
null |
|
|
| geography_id |
int4 |
10 |
√ |
|
null |
|
| Geographies.id
|
DemandServiceDemands_geography_id_fkey R |
|
| final_energy_index |
bool |
1 |
√ |
|
null |
|
|
| demand_technology_index |
bool |
1 |
√ |
|
null |
|
|
| other_index_1_id |
int4 |
10 |
√ |
|
null |
|
| OtherIndexes.id
|
DemandServiceDemands_other_index_1_id_fkey R |
|
| other_index_2_id |
int4 |
10 |
√ |
|
null |
|
| OtherIndexes.id
|
DemandServiceDemands_other_index_2_id_fkey R |
|
| interpolation_method_id |
int4 |
10 |
√ |
|
null |
|
|
| extrapolation_method_id |
int4 |
10 |
√ |
|
null |
|
|
| extrapolation_growth |
float4 |
8,8 |
√ |
|
null |
|
|
| geography_map_key_id |
int4 |
10 |
√ |
|
null |
|
|